
In praise of Hyper-V
 I’ve been using virtual machines for years. Originally I started with VirtualBox, the free VM manager from Oracle. I’m not sure why I switched to Hyper-V, about five or six years ago but I’ve been on Hyper-V since then. You need to be on Windows Pro and have at least 8 GB though the more RAM the better. I have 64 GB and the most I’ve ever had in use at one time is 29 GB. I always try to keep RAM use below 50% as there’s less disk swapping.
I’ve been using virtual machines for years. Originally I started with VirtualBox, the free VM manager from Oracle. I’m not sure why I switched to Hyper-V, about five or six years ago but I’ve been on Hyper-V since then. You need to be on Windows Pro and have at least 8 GB though the more RAM the better. I have 64 GB and the most I’ve ever had in use at one time is 29 GB. I always try to keep RAM use below 50% as there’s less disk swapping.
VMs are an excellent way to try out other Operating systems, install software and venture outside the comfort zone of a Windows PC and Windows 10. Many of the screenshots published here in earlier posts have come from Ubuntu 18.04 LTS running in Hyper-V. It takes a minute to fire it up and connect then login.
I learnt to use Linux that way, both via the Ubuntu GUI and terminal commands and much of my 2nd Ebook has been tested on a Raspberry Pi OS running in a VM. Of course it lacks the hardware of the real Pi, so I have to test programs on both, but it’s quite a bit quicker doing a screen grab using the commercial Snagit on my Windows 10 PC.
I can do screen grabs on a PI using scrot, but then I have to upload the image using WinSCP or Putty. It’s not the end of the world but when you are doing a lot, having the image in the Snagit editor ready to copy/paste is a time saver. Also in a similar way, make sure you can do copy/paste via the clipboard and can resize the guest OS (as it’s called). It makes a difference.
I have mine configured so its uses RDP and you can just see the corner of the RDP bar in the Ubuntu image below where I’ve just launched Visual Studio Code.

From a terminal I did ifconfig and got
eth0: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500
inet 172.21.212.121 netmask 255.255.240.0 broadcast 172.21.223.255
inet6 fe80::2b71:6d6b:9a09:9aae prefixlen 64 scopeid 0x20
ether 00:15:5d:38:01:03 txqueuelen 1000 (Ethernet)
RX packets 47317 bytes 69248755 (69.2 MB)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 27622 bytes 1791175 (1.7 MB)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
and on Windows
C:\Users\David>ping 172.21.212.121
Pinging 172.21.212.121 with 32 bytes of data:
Reply from 172.21.212.121: bytes=32 time<1ms TTL=64
Reply from 172.21.212.121: bytes=32 time<1ms TTL=64
Reply from 172.21.212.121: bytes=32 time<1ms TTL=64
Reply from 172.21.212.121: bytes=32 time<1ms TTL=64
This makes it very handy for testing network servers or if you do web development running a web server locally.







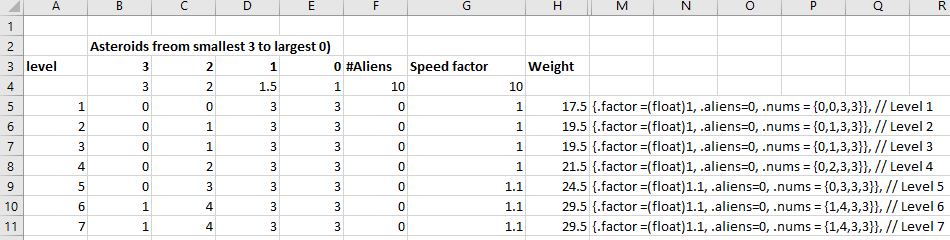 In the asteroids game and shortly in my MatchThree game, I’ll be creating a level data array of struct. This has a struct for each level containing a count of particular features for that level.
In the asteroids game and shortly in my MatchThree game, I’ll be creating a level data array of struct. This has a struct for each level containing a count of particular features for that level.
