I knew it wasn’t going to be easy, but it turned out to be quite a bit more difficult than I thought.
The problem is, unlike SDL2, there are no dev versions of SDL3 etc. yet, so you have to build it from scratch.
I’ll be honest, I’m not sure I could have done it without this GitHub repository. User Ravbug who is very busy person (752 contributions on GitHub in the last year- I tip my hat to him or her!) who provided that repository.
It sets up SDL3, SDL_image, sdl_mixer and SDL_ttf.
Follow his link to the Wiki page Scroll down to the bottom for the Linux instructions. I can confirm that it works on Raspberry Pi as well. You’ll need to install cmake first with
sudo apt install cmake
Then run his cmake to build everything and go for a coffee.
Now go into the build folder under sdl3-sample and do
make
That only takes a second or so.
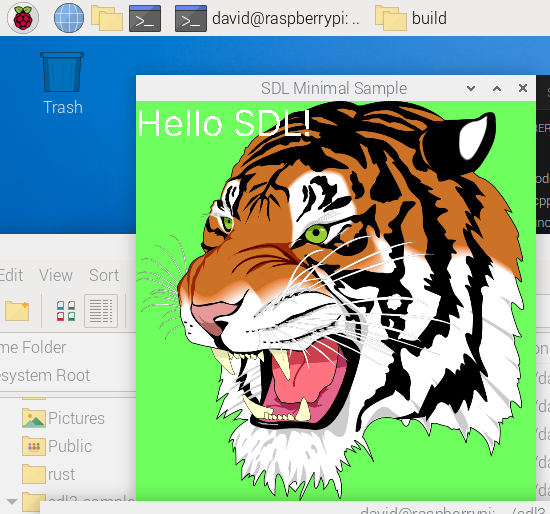
After you’ve done that you’ll end up with a load of files including an executable sdl-min that you can run. That’s what generated the Tiger’s head – it plays The Sting film’s theme (The Entertainer) music as well demonstrating that it’s using SDL_mixer as well as SDL3 and SDL_ttf (I’m guessing) and of course SDL_image.
But that is just the start
To use SDL3 etc in your C program, you need a bit more configuration than with SDL2. I’m in uncharted waters here but used an AI- Claude 4 to help me get through and it did.
The problem is you have to tell VS Code where the header files are located, the .so files and also the executable needs to know at runtime.
I set up Ravbug’s sdl3_sample in my home folder so all paths start /home/david/sdl3-sample.
This is my tasks.json
{
"version": "2.0.0",
"tasks": [
{
"type": "shell",
"label": "clang-14.0 build active file",
"command": "/usr/bin/clang-14",
"args": [
"-I/home/david/sdl3-sample/SDL/include",
"-I/home/david/sdl3-sample/SDL_image/include",
"-I/home/david/sdl3-sample/SDL_mixer/include",
"-I/home/david/sdl3-sample/SDL_ttf/include",
"-g",
"${file}","${workspaceFolder}/hr_time.c",
"-L/home/david/sdl3-sample/build",
"-Wl,-rpath,/home/david/sdl3-sample/build",
"-o",
"${fileDirname}/${fileBasenameNoExtension}",
"-lSDL3",
"-lSDL3_image",
"-lSDL3_ttf"
],
"options": {
"cwd": "/usr/bin"
},
"group": {
"kind": "build",
"isDefault": true
}
}
]
}
The lines that are SDL3 specific include the -I’s to provide the include path. -L the path to the .so files and the -rpath line is the path to the runtime files which gets linked into the executable.
If you add these three lines into c_cpp_properties.json then you’ll also avoid the dreaded red squiggles.
"includePath": [
"${workspaceFolder}/**",
"/home/david/sdl3-sample/SDL/include",
"/home/david/sdl3-sample/SDL_image/include",
"/home/david/sdl3-sample/SDL_ttf/include"
],
And your C’s #includes need the files prefixed like this :
#include <SDL3/SDL.h>
#include <SDL3_image/SDL_image.h>
#include <SDL3_ttf/SDL_ttf.h>
And here it is running on my Pi.



 I wrote a Poker Hand evaluator. It read in a file of a 1,000 randomly generated sets of seven cards like this AC 8H JC …and figured out what was the best hand. It’s in Rust and on
I wrote a Poker Hand evaluator. It read in a file of a 1,000 randomly generated sets of seven cards like this AC 8H JC …and figured out what was the best hand. It’s in Rust and on 
 Now the only pain with debugging is that the application must be running for Visual Studio to attach to it. I was debugging a utility that is run, does its business and closes. So to debug it, I added this as the first line in main() in program.cs
Now the only pain with debugging is that the application must be running for Visual Studio to attach to it. I was debugging a utility that is run, does its business and closes. So to debug it, I added this as the first line in main() in program.cs
 Remember the cellular automation Life? I covered it in previous blog entries
Remember the cellular automation Life? I covered it in previous blog entries