
How to debug programs using SDL
 There’s nothing worse than a program halting with a simple “Segmentation fault” and no idea where or why. It happened to me today working on the 2nd eBook (for Raspberry Pi) and I had to figure out where it was going wrong.
There’s nothing worse than a program halting with a simple “Segmentation fault” and no idea where or why. It happened to me today working on the 2nd eBook (for Raspberry Pi) and I had to figure out where it was going wrong.
In the end it was a really silly bug, I was trying to load masks but had left the masks/ folder out of the filename.
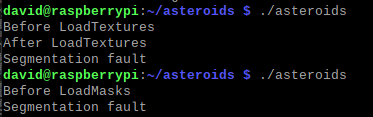
How did I find it? I sprinkled a few fprintf(stderr,”message”); throughout the program changing “message” to something appropriate and launched it from a terminal. I’d thought it was in a function LoadTextures() so added a call before and after but you can see that worked and the segmentation fault happened after LoadTextures().
So I added it before and after LoadMasks() and my second run it happened before it reached the After LoadMasks message.
Note, I used stderr as the output path because, unlike stdout which is buffered and can be cleared, anything sent to stderr appears immediately. More about this in this offsite article.
The using SDL part of the title is just to show that you can find bugs even in programs that use SDL.







