Originally I was going to use Tiled to draw hexagons in a Flutter web game. But it seemed easier to do it manually without having to worry about working with the .tmx format which is an all singing format based on a XML file structure, and seems more suited to static maps.
My game includes a map generator although that’s not hooled up yet.
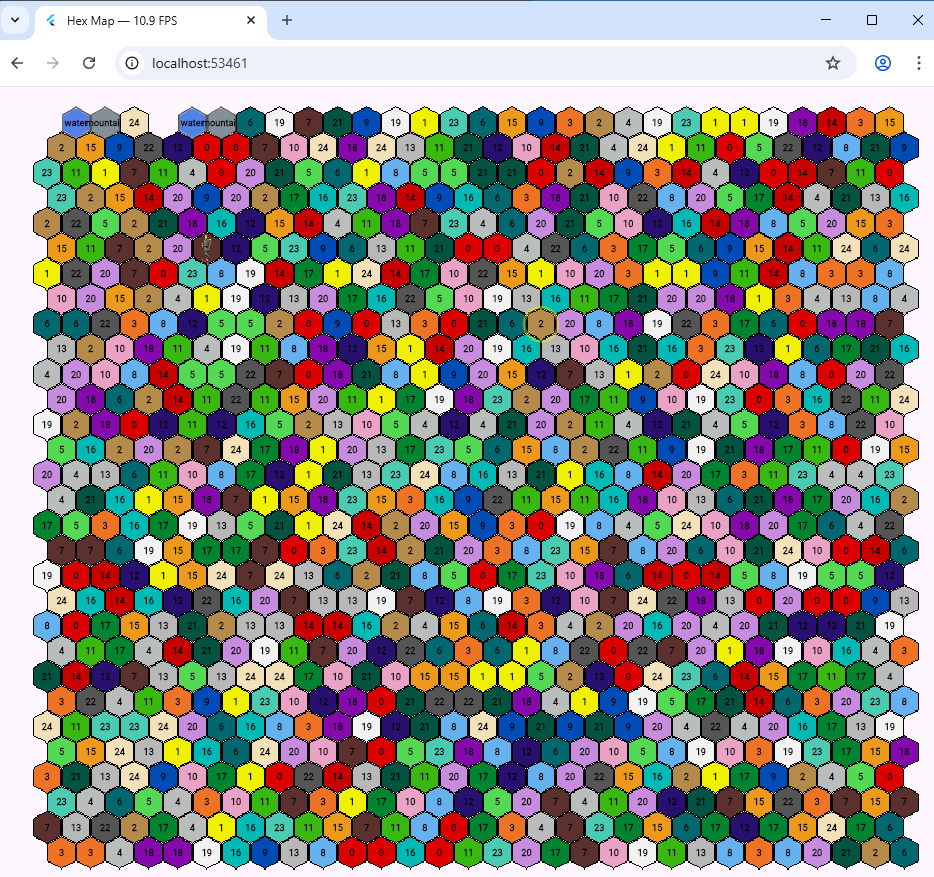
I’ve been doing experiments and have a Flutter web program displaying a 40 x 40 hexes map, complete with text. It does this at around 6-10 fps. This is on a 3 1/2 year old PC. I think it should be sufficent frame rate for a web strategy game. It also displays images and there’s a faint one on the sizth row.
If you look very closely in the middle of the ninth row you might see a hex with the value 2 that’s been clicked on with a faint circle highighting it.
The hexes aren’t quite meshing together with a solid border so that needs sorting.
So I’m developing a web postal* game client which is loaded from a Linux server as a Flutter web app. When I run it on the Linux box from Chromium, no problems, it loads a binary file ok. When I try to run it from a networked Windows box, the binary file fails to load. It’s loaded by calling a PHP endpoint, passing the path of the file to a PHP script.
It was my fault. Because the game client is loaded from the Linux server and the path is a Linux path to the binary file, I’d missed that it runs on the Windows box (where the browser launches from). I’d used Platform.isLinux and Platform.Windows calls to figure out the path when I initially tested it on a Windows box. The path to the binary file was being sent as if the file was on the Windows box because the Flutter app runs as JavaScript in the browser there. D’oh!
*Postal means a game where the game client sends orders to the server. Those are processed once an hour and the results file is picked up when the client next runs. It’s how games used to be played through the post back 30 or 40 years ago hence the name.
I’m working on a game with a Flutter web client and two Dart terminal programs hence the visual pun. Annoyingly, you can’t compile a Dart exe for Linux on a Windows PC. You can do that in C# but I prefer to use Dart.
I have all the classes in two files (one is called classes.dart) and because I’m using JSON to persist game data, I use the build_runner package from pub.dev. Just add this before any classes:
@JsonSerializable()
Make sure if you have enums that every enum value has
@JsonValue('houses')
before it and add functions like this for each class you want to persist; in this case a Location class:
Then when it’s all done, do this to generate a file that handles loading and saving the specified classes.
dart run build_runner build
Along the way though I managed to get Flutter into a Dart program. I’m using SQLite but only in Dart, not in the Flutter app. Unfortunately I used the kIsWeb constant to exclude some calls (when the classes are used by the Flutter app) in my classes file. But you can’t do that in a pure Dart program, it will not compile. Instead I wrote my own function.
I’m aware that C is notorious for unexpected behaviour (UB). Let me describe this bug:
My second game in C + SDL for my newest eBook is Match Three and compiled with Clang-11 on my Raspberry Pi 4B. I’m getting a weird bug that doesn’t occur when I compile it on Windows under MSVC; the only differences between the source code on the PI and Windows are the paths to SDL and the sn._s calls but there aren’t many of those. Also I compiled it with clang-14 on Ubuntu 22.04 LTS on a Hyper-VM and that behaves properly.
Each piece is held a struct in a 10 x 10 array. One field is called size. It’s 0 normally but if it is set to a value, typically 64 then it counts down, one per frame and the piece is drawn rotated by 8 degrees each frame. When it reaches 0 the piece is removed. This is my “down the plughole” way of removing pieces. It takes exactly 64/60 seconds to vanish. I use the size field to draw it when size is non-zero so it shrinks as it rotates It’s a nice effect.
The bug though is that when it starts up, several pieces start rotating and keep rotating. The size field stays at 63. There’s no code that explains this behaviour and it only happens on the Raspberry Pi, not on Windows or on Ubuntu. Is it a compiler bug or some weird UB on the PI version. It’s an interesting bug and I’ve only wasted a week of evenings on it so far!
I’ve since discovered since I got a Raspi 5 that the install-tools are no longer built and included when you install SDL2 which means controllermap used in this article isn’t easily available.
However the source code is available (and all the tests) and only needs a bit of tweaking to build it on a Raspberry Pi.
I will add a tutorial to build it and will link to it once done.
— Rest of article —
I’ve been working on my 2nd eBook and adding a GamePad is a thing I need to explain. You can see them in earlier blog posts:
But I want readers of the book to be able to generate their own controller maps. I cannot assume that everyone has access to Windows.
What I didn’t know back then is that SDL comes with a game controller map generator application called (subtle this!) controllermap that you can run on your Pi or Linux computer.
I had to use the File Manager Find file facility to locate it. It’s in the installed-tests folder for SDL2 or more precisely /usr/lib/aarch64-linux-gnu/installed-tests/SDL2 on my Raspberry Pi running 64-bit Raspberry Pi OS.
On my VM Ubuntu I found it in /usr/lib/x86-64-linux-gnu/installed-tests/SDL2
I did a bit of experimenting with a clean Raspberry Pi OS setup and then I installed libsdl2-dev and saw the installed-tests/SDL2 folder installed, so that’s what you need. So install the dev files as per New tutorial on installing SDL on Linux.
Plug in a gamepad and on your Pi, cd into that folder (the Pi one not the Ubuntu one!) and in a terminal run ./controllermap
It will open with your B button highlighted. Press your B button. In the picture above it’s the circle on the right hand side that is the lowest of the four or the yellow button in this picture of my controller.
It will then go through every possible button. Just press the corresponding button or space key if you haven’t got that. Compared to the main picture, mine lacks the two bottom joysticks, the buttons between the Stop and Start buttons and the two trigger buttons at the top. For each of those just press the space bar. Eventually it will loop back to the B button. Just press it and it will finish and output the gamepad control map.
It outputs two copies of this. You can send one to a text file in your home folder by doing
./controllermap >~/gamepad.txt
but you will have to press all the buttons etc. again. This is what my Pi gave.
A reader asked me how to setup SDL2 for Windows given recent changes in SDL2. Specifically the files and libsdl projects have been moved from the libsdl.org website to GitHub. You can easily find SDL2 Image, Mixer, TTF etc.
However it can still be quite daunting setting up Visual Studio for SDL2. You have to download the specific files, then configure the project properties to specify the include paths for header files and then the lib files, both the path to them and identify the ones you want to use.
As I’m on my new PC, I bit the bullet and went through the process of setting it up. It took just over an hour to configure it. I’ve put it into a PDF that’s a couple of pages long.
So the game works but only after I disabled the sound code; it was failing in the call to Mix_OpenAudio(). I think recent work on the SDL Mixer needs some work on my part. I need to sit down and look at the SDL Mixer page and figure out what’s failing. Once that’s done, I’ll update the files.
I spent several years in the 1980s programming games.
I have a memory of 26 year old me sat hunched over a computer late at night back in 1985. I was working a 60-70 hour week as a partner in a games company. My current game was an American Civil War tactical wargame called Johnny Reb II. I was struggling with some ‘artificial intelligence’ code for the attackers (Confederate troops) to cross a bridge over a river. On the other side the defenders (Union) were trying to defend the bridge.
Artificial Intelligence in games is a completely different thing from ML and Data Science nowadays. Back then it was just a control algorithm for troops reacting to the presence of enemy troops and working out the best routes, targets to attack, whether to retreat and so on.
What made it worse was that the whole thing was written in 6502 assembly language (and later converted to Z80). Back then you had two choices: Basic which was to be honest slow and clunky for writing games or assembly language. If I was doing it now, without a moments hesitation I’d program it in C. But C compilers for 6502 didn’t exist back then.
The Problem with assembly language
The problem with assembly language is (a) it’s slow to write. You can write 10 lines of C in the same time as ten lines of assembly code. Those ten lines of C will do far more than ten lines of assembly code. In 6502 all you are doing is moving values between registers or register <> memory. Maybe add a number or increment one of the three available registers A, X or Y. These were all 8-bit registers so you couldn’t even index easily through 64-bit memory. To do 16-bit indexing you stored the 16-bit address in two successive page-0 locations (addresses 0-255) and then used Y as an 8-bit index. You could do the same in page 0- memory with the X register.
(b). It takes a lot of code to do anything in assembly language. You want floating point arithmetic in 6502? Take a look. I think Steve Wozniak wrote those for the Apple I/II. What we take for granted in languages like C# or Java or JavaScript is code for high level data structures like dictionaries. I’m sure it could be done but it takes a fair bit of programming. You don’t have those in assembly language; all you have to use is simple and not very long arrays.
In C# I wrote a program to read a 46 MB text file and produce a sorted count of all words in the file. It used a Dictionary, took me 30 minutes to write and it ran in 5 seconds. It would take weeks to do the same in assembler.
6502 Page 0 locations were valuable because they made your code both shorter and faster.
I wrote a cross-assembler for 6502 in Z80 as a way to learn Z80. Assemblers use labels (L20, L30, L31 etc. in the screenshot) and I needed a way to hold them efficiently in memory. I ended up with a 26 x 26 index table of 2 byte pointers. If you had a label ‘ROUTE’ then there would be a pointer to a chain at the location for [‘R’][‘O’]. Each entry in the chain was like this
1 byte length of rest of label (i.e. 3 for ‘UTE’) – 0 marks the end of the chain.
3 bytes to hold ‘UTE’.
2 byte address value
No need to hold the whole word as you know the first two letters. It also makes comparing a label against one in the table was faster because it only needed to match against len(label)-2 characters.
So the next value in the chain would start after that or be a 0 for the end of the chain. Yes most of the index table might be empty (all 26x26x2= 1352 bytes) but every label in a chain used 2 bytes less than the full label text. So with more than 676 labels you saved memory. Searching for a label was just a matter of walking a chain. Labels were just addresses; so a location could hold a value like a count. You’d identify it with a label and use that label in 6502 instructions. No variables in assembler; it’s all addresses…
With 6502 you need to do two passes to generate code. If you have a label in the first page of memory (0-255) then instructions are only two bytes long and are faster to execute than the three byte instructions. So on the first pass you don’t know if a LDA label will be 2 or 3 bytes long. After the first pass through though you do know now, so on the 2nd pass it can output the correct size instructions.
Programming in assembler means you have to write a lot of code and in the early days before I had a development machine that meant I had to save the source code to tape and compile it using a cartridge assembler. The CBM-64 could take cartridges and one of them stored assembly language in RAM just like Basic. If the game did something wrong then the CBM-64 would reset and you’d lose your source and have to reload it from the slow tape. Let’s hope you didn’t forget to save changes before you ran it. I spent a few hours gnashing my teeth over a persistent crash. I was calling a CLR routine when it should have been CLS! d’oh…
So a game back then might be 5,000 lines of code or longer. That’s quite a bit to hold in memory, given that you need space for the game machine code, sprites, graphics etc. as well. Plus it’s wasteful having to recompile the same code over and over again. My cross-assembler did 250 lines per second but divide that by two for the two passes.
So I split up long files into smaller ones and created a jump table at the start. There was no linker so the code was loaded into RAM at fixed addresses. If you had five subroutines in one file then there’d be five jumps at the start to the actual function. And the files that called those functions just had a block of five calls at the start.
That way you didn’t have to worry exactly where the function was located in RAM so long as that file was always loaded at the same address.
Switching to Development Machines
It got easier when we switched to development machines. The CBM-64 had a parallel port as did the development machine (Tatung Einstein-a CP/M computer) so a little bit of handler code in the CBM-64 set up the CIA chip to wait for data sent down the parallel cable and put the code directly in RAM. It took no time to load the handler from tape after a crash and then send down the whole file.
Modern CPUs do all sort of optimizing tricks and that’s even before you use vectorization. Compiler writers know how to generate code that uses these tricks but it would take quite a while to learn them so you could use them in hand-written assembly.
Conclusion
Writing in assembler in the 80s was easy to learn. Nowadays I wouldn’t know where to start- the Intel and AMD CPUs have a lot of different chips in their families so there are variations in what instructions are available. Oh and don’t forget there’s ARM CPUs as well.
Writing in C (or even C++) is a lot easier to get into and I very much doubt if you’d get any better performance in writing things in assembly. Also, it would take a lot longer.
Back in May 2020 (nearly two years ago) it was originally announced and the updated release date now looks to be late 2022. Also it’s $179 not $149. But they have given a lot more details; you can for instance see the hardware spec.
Also more relevant is the way of creating games. Either in Lua + C or just C. The dev tools illustrated are running on a Mac but according to this Twitter thread (worth a read), they’re available for Windows, Mac and Linux. The SDK looks impressive enough- “It includes helpful functions for things like font handling, drawing, animation, sprites, tilemaps, collision detection, A* pathfinding, audio synthesis, crank handling and more. You can download the SDK which includes a simulator now from the dev page..
Would I get one? I’m toying with the idea. A mono display of 400 x 200 is a bit retroish and my days of creating those types of games are probably long behind me, but it’s tempting.
I’m working on three game projects (my side projects), One is Flutter front end plus C# back end, another is the same but a different type of back end and the third is a mobile game with C# backend but its put to one side until the others are done. These are all side projects.
I’ve bought graphics and they do up to a point- e.g. kenney.nl is very good. But sometimes you need something a bit better or that’s not covered by that library.
Now one of the things I’ve done is use low costs artists from sites like Fivesquid.com and fiverr.com. Many of these artists are very good but live in countries where things are a lot cheaper than here in the West. Exploitation? Maybe, but they are happy to do the work and it saves me a fortune. What might cost me a couple of hundred pounds here in the UK can be done for say £20.
But I’ve found when dealing with them that you can’t take anything for granted. You have to have a bit of patience and explain everything including your expectations. And make sure you nail the price down exactly. I had arranged everything with one to do 35 small graphics and he wanted £35 for each graphic. Despite his advert saying 5 graphics for £10!
So I’ve found, you need to specify file format (.png or .jpg), layout- single files or in a sheet in a grid. Also fivesquid have a thing where when the order is delivered, you have three days to mark it complete or asks for changes. One artist said it was complete but hadn’t quite got it ready and the three day period expired before I’d received anything. So I could hardly accept nothing. It was though a genuine mistake on the part of the artist and I did get the graphics eventually.
One of my favourites and one that I actually bought twice in my life and of course I have mentioned before. Originally I bought it back in 1982 and more recently in 2015 along with the sister “More Computer Games” book. The reason I mention it because there’s an ongoing project to do the games in it in languages other than BASIC.
The languages they’ve chosen are:
Java
Python
C#
VB.NET
JavaScript
Ruby
Delphi / Object Pascal
Perl
I no, it’s sad. No C… But given that it includes C#, I’ll let them off.

 Originally I was going to use Tiled to draw hexagons in a Flutter web game. But it seemed easier to do it manually without having to worry about working with the .tmx format which is an all singing format based on a XML file structure, and seems more suited to static maps.
Originally I was going to use Tiled to draw hexagons in a Flutter web game. But it seemed easier to do it manually without having to worry about working with the .tmx format which is an all singing format based on a XML file structure, and seems more suited to static maps.

 I’m aware that C is notorious for unexpected behaviour (UB). Let me describe this bug:
I’m aware that C is notorious for unexpected behaviour (UB). Let me describe this bug: Updated 20/03/2025
Updated 20/03/2025
 A reader asked me how to setup SDL2 for Windows given recent changes in SDL2. Specifically the files and libsdl projects have been moved from the libsdl.org website to GitHub. You can easily find SDL2 Image, Mixer, TTF etc.
A reader asked me how to setup SDL2 for Windows given recent changes in SDL2. Specifically the files and libsdl projects have been moved from the libsdl.org website to GitHub. You can easily find SDL2 Image, Mixer, TTF etc. I spent several years in the 1980s programming games.
I spent several years in the 1980s programming games.


 I’m working on three game projects (my side projects), One is Flutter front end plus C# back end, another is the same but a different type of back end and the third is a mobile game with C# backend but its put to one side until the others are done. These are all side projects.
I’m working on three game projects (my side projects), One is Flutter front end plus C# back end, another is the same but a different type of back end and the third is a mobile game with C# backend but its put to one side until the others are done. These are all side projects. One of my favourites and one that I actually bought twice in my life and of course I have mentioned before. Originally I bought it back in 1982 and more recently in 2015 along with the sister “More Computer Games” book. The reason I mention it because there’s an
One of my favourites and one that I actually bought twice in my life and of course I have mentioned before. Originally I bought it back in 1982 and more recently in 2015 along with the sister “More Computer Games” book. The reason I mention it because there’s an