

I added an if and switch tutorial

The next tutorial is Simple control flow in C. This demonstrates how to do if, if else and then switch statements. These are pretty siomple concepts but they are fundamentals so you do need to know them.
One thing I didin’t show in the switch tutorial is that you can mix in labels for that real write-only code experience. It’s not a technique I recvommend which is why its NOT in the tutorial but if you promise never to use this except in the rarest of circumstances, here’s what I mean.
#include <stdio.h>
int main() {
int a = 10;
switch (a) {
case 1:
case 2:
case 3:
case 4:
{
printf("a<5\n");
break;
};
case 5:
fred:
case 6:
printf("a ==5 or a ==6\n");
break;
case 7:
case 8:
case 9:
printf("a <9\n");
case 10:
{
printf("a=10\n");
goto fred;
}
default:
printf("a not in range 1-10\n");
break;
}
}The label is the line fred: and you can see in case 10 that after printing “a=10\n”, it jumps to fred which is just after the 5 case. That does nothing and falls through to the 6 case where it prints out “a ==5 or a ==6\n”. It’s not recommended but at least now if you ever see a jump to a label in a switch statement you can be sure that the programmer was not really at the top of his or her game.
I like web games
 Not the Flash type games you get on sites like Kongregate but strategy games like Illyriad, (Pictured) Though you can waste an awful lot of time playing them. The web is an excellent platform for certain of multiplayer games. Heck you can even play games like Quake III which was a desktop game but redone using WebAssembly.
Not the Flash type games you get on sites like Kongregate but strategy games like Illyriad, (Pictured) Though you can waste an awful lot of time playing them. The web is an excellent platform for certain of multiplayer games. Heck you can even play games like Quake III which was a desktop game but redone using WebAssembly.
I used to play a strategy game Inselkampf (German for Island war) where you start off with one island and improve it then you can start building ships and invading other islands. I remember getting to the point where I was managing an empire of 80 islands and the only way I could do track all the details was with an Excel spreadsheet. But it was a big time hog, taking up over and hour and a half each day (just mad!) and I stopped playing.
It seems to have closed down a few years ago which is a shame as it was very popular in the mid 2000s. The UK website inselkampf.co.uk just has a start Game Over message on it! Searching about I even found a copy of the Inselkampf rules online.
Given my postal games background (I created three Play by Mail games back in the late 80s, two of which are still run today on kjcgames.com. ) I still have an inkling to create a big web or mobile playable game. I’m not saying I’ll make a £million like torn.com. I’m not a great fan of web development (well the JavaScript part of it) but I’m currently studying a Udemy course on Blazor which is Microsoft’s take on C# and WebAssembly. This lets you create websites in C# running in the browser. And C# I am most definitely a fan of.
The L game by Edward de Bono

I bought a book The Five Day course in Thinking by the author Edward de Bono when I was at University. It included a seemingly very simple two player strategy game called The L Game. If you’ve heard of the phrase Lateral Thinking that was invented by him back in 1967.
On a 4 x 4 board there are two L shapes and two neutral single pieces. To win you just have to move your L shape and (optionally) one of the neutral pieces so that your opponent can’t move his L shape.
I’ve had a cursory search for C source versions of this game and there are bound to be more than the one I found which was written for an Arduino WifiBoy Pro. There’s a downloadable zip file which contains a file wbpro_chess_L.ino. Despite the extension, it is a C source code text file.
If you are looking for an interesting programming problem then create a computer opponent for a game. The good thing about this is, its so simple graphics wise that you could draw the board in a console with B = Blue, R = red and 1 and 2 the two neutral pieces like this.
1RR. .BR. .BR. .BB2
New tutorial on installing SDL on Linux
 Well you might say, “Don’t many Linux distros have SDL installed so people can play games?” and the answer is yes but not the development files and headers, and that’s what this shows you how to do along with a simple program to test that you can compile and run.
Well you might say, “Don’t many Linux distros have SDL installed so people can play games?” and the answer is yes but not the development files and headers, and that’s what this shows you how to do along with a simple program to test that you can compile and run.
You’ll also need clang or gcc installed but as you can do that with a simple sudo apt install clang, it’s hardly worth a tutorial on its own.
However you also need to install VS Code and the C/C++ extension. Go to the VS Code website, download the Linux x64 version and double click on it to install it. After that from a terminal type code and it’ll appear. You then need to select extensions (5th icon down the left hand side) and pick the Microsoft C/C++ extension and install it.
I’ve added a new tutorial on the Tutorials page How to Install SDL on Linux. That includes a link to a demo file (its just above the screenshot) containing all three source code files and four VS Code configuration files for VS Code.
This program is almost identical to the asteroids_ch25 file (it draws lots of random size and colour rectangles on screen) but has been upgraded for Clang 10 and also what looks like a bug with search paths. There’s an extra line in Tasks.json to include the path to the SDL2 header files or you’ll get a can’t find a particular SDL header error when you compile.
Building code with VS Code is easy to understand once you “get” how the Folder works. I always keep the .vscode folder in there with the four C/C++ JSON configuration files and all source for that whatever it is you are compiling. In the screenshot below (from WinSCP), you can see the path is /home/david/Projects/Examples and it contains the .vscode folder the three source files and demo which is the compiled code. In VS Code I opened Examples as the Folder.

The .vscode folder is greyed out because the . means it’s normally hidden.
Coding a text adventure in C
 Text adventures have been around since the likes of Colossal Cave which I first played in 1980. They were quite popular on the early home computers like ZX 81 which were quite limited in RAM and capability. With the capacity of modern computers there are Interactive fiction (the modern name for adventure games) games with over a million words of text.
Text adventures have been around since the likes of Colossal Cave which I first played in 1980. They were quite popular on the early home computers like ZX 81 which were quite limited in RAM and capability. With the capacity of modern computers there are Interactive fiction (the modern name for adventure games) games with over a million words of text.
I suspect I’d probably want to code them in another language because C isn’t the best language when it comes to text. Nevertheless other have gone ahead and there’s an almost complete (20 out of 23 lessons) on how to program a text adventure in C on GitHub.
It’s a fine piece of work and some of the 20 articles like 20. Combat are quite long with lots of annotated code. At the bottom of each page you can download the source code on that page as a zip file or run the sources on repl.it. If you are learning C the line-by-line annotations really help explain why something was done.
The C template library
 C of course doesn’t have generics or templates like C++ does, but I came across Gustav Lou’s C Template library this morning. It provides C equivalents to the following C++ template libraries. Each is done as a header file that you include.
C of course doesn’t have generics or templates like C++ does, but I came across Gustav Lou’s C Template library this morning. It provides C equivalents to the following C++ template libraries. Each is done as a header file that you include.
deq.h -> std::deque
lst.h -> std::list
pqu.h -> std::priority_queue
que.h -> std::queue
set.h -> std::set
stk.h -> std::stack
str.h -> std::string
vec.h -> std::vector
The page on GitHub shows how to use libraries with an example of vector. The string equivalent library str.h would be an interesting one to see just how much of C++ string is supported. C would still never be my language of choice for anything text heavy but if this is better than strcpy, strcat etc. I’ll happily use it. Likewise list and vector. From memory C++ std::array is just a wrapper around the C standard array!
A possible defer mechanism for C
 I remember that some other programming language (possibly Go) has a defer mechanism. You can tell it to defer a function call until the end of the function. I think this means, even if you do an early return that all functions that have been deferred will still run. It’s a handy language feature. Alternatives to it ion say C# are try … finally where the finally ensures that code gets runs.
I remember that some other programming language (possibly Go) has a defer mechanism. You can tell it to defer a function call until the end of the function. I think this means, even if you do an early return that all functions that have been deferred will still run. It’s a handy language feature. Alternatives to it ion say C# are try … finally where the finally ensures that code gets runs.
The reason for mentioning this is it’s a possibility for a future inclusion in the next C standard. There’s a quite long article about defer listing benefits. But even better the author Jens Gustedt has provided a reference implementation of it on GitLab.
I’m all in favour of this. Adding new features to C is not something to be done lightly but error checking and handling in C has always been a bit iffy. I’ve never used a SetJmp for example. I do hope that defer gets added to C though I can’t see it being there for a few years.
Tilengine – for creating Retro games
 Tilengine is an open source, cross-platform 2D graphics engine in C for creating classic/retro games with tile maps, sprites and palettes. It’s intended use is for developing 2D games of old.
Tilengine is an open source, cross-platform 2D graphics engine in C for creating classic/retro games with tile maps, sprites and palettes. It’s intended use is for developing 2D games of old.
Written in C99, it can be used on Windows (32/64), Linux PC(32/64), Mac OS X and Raspberry Pi. Internally it uses some SDL2 libraries. There are bindings for other programming languages as well as native support for C/C++.
You’d use this for parallax effects using sprites over background layers. It makes it easier than coding yourself. In particular sprite animation is excellent with pixel perfect collision detection and 17 different functions for manipulating them. Rather than roll my own in my Asteroids game I could have used this.
The other documentation is a little spare with placeholders, but I imagine you can work it out from the header files and samples.
How to read a text file into memory in C
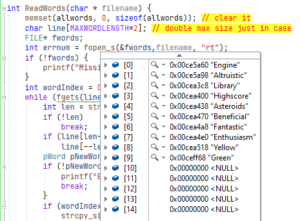 As part of the crossword grid packing utility, the first stage is building the list of words in a structure in RAM. To keep thing simple I’m going to use an array of char * pointers. The array is limited to a maximum 20 words. If any more are read then they will be discarded.
As part of the crossword grid packing utility, the first stage is building the list of words in a structure in RAM. To keep thing simple I’m going to use an array of char * pointers. The array is limited to a maximum 20 words. If any more are read then they will be discarded.
Just to prove that it worked, I wrote this in Visual Studio and ran it in the debugger. You can see elements 0-9 in the screenshot with the source code in the background.
This is the listing of the program. Note, it doesn’t have a function to free up the memory dynamically allocated for each of the words.
You might wonder about these lines (25 and 26).
if (line[len-1] == '\n')
line[--len] = '\0';This is needed because when you use fgets to read a line of text it includes a line feed at the end. So the first line in the file Engine is actually 7 characters long with a terminating \n. The malloc on line 27 allocated enough RAM for len + 1 to allow for the terminating 0 at the end of each string. In line 33, if you are on Linux replace strcpy_s with strncpy. Both are safe versions of strcpy. Here’s the full listing.
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <time.h>
#define MAXWORDS 20
#define MAXWORDLENGTH 32
typedef char* pWord;
pWord allwords[MAXWORDS];
int ReadWords(char * filename) {
memset(allwords, 0, sizeof(allwords)); // clear it
char line[MAXWORDLENGTH*2]; // double max size just in case
FILE* fwords;
int errnum = fopen_s(&fwords,filename, "rt");
if (!fwords) {
printf("Missing word file %s", filename);
}
int wordIndex = 0;
while (fgets(line, MAXWORDLENGTH, fwords)) {
int len = strlen(line);
if (!len)
break;
if (line[len-1] == '\n')
line[--len] = '\0';
pWord pNewWord = (pWord)malloc(len + 1); // line 27
if (!pNewWord) {
printf("Error allocating memory");
break;
}
if (wordIndex < MAXWORDS) { // can add to list
strcpy_s(pNewWord, len+1, line); // line 33
allwords[wordIndex++] = pNewWord;
}
}
fclose(fwords);
return wordIndex; // = Count of words
}
int main() {
int numWordsread = ReadWords("words.txt");
}