If I were to use a database in a game, it’s likely that it would be SQLite. It’s an open source SQL database that is 102 different C files and 32 others. Of those 102, 75% are C and the remainder header files.
Unlike many other SQL databases (for example MySQL, SQL Server, PostgreSQL) it doesn’t need to run as a separate server. It compiles directly into your application, adding a whopping 400 KB! (I’ve seen bigger picture files…) It’s fast and very well tested. For every line of code there are 644 lines of test code! Details of testing here.
You wouldn’t use SQLite in an arcade game as it would be a bit of an overkill just to hold a high-score table, but in something like a Rogue or Mud game, I could easily see it being used to store rooms, corridors, treasures etc. SQLite is also very easy to use.
The word amalgamation means that all the 102 source files have been combined (amalgamated) into one file called SQLite3.c. So building it is a single command.
SQLite is probably the worlds most popular database. It’s found in most operating systems and is used in every smartphone.
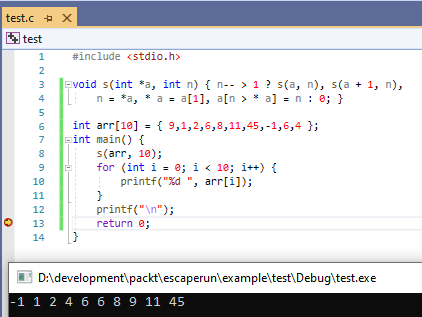
I came across this article on efforts to make the smallest sort function in C. Being cynical I did wonder if it would compile and run. I mean 56 bytes is kind of short!
To get it to compile in VS 2019 I had to add a couple of changes, mainly ints and the void. This is it wrapped in a program. The screenshot shows it running and the output at the bottom. Very clever!
The sort function is that void s(… at the top.
#include <stdio.h>
void s(int *a, int n) { n-- > 1 ? s(a, n), s(a + 1, n),
n = *a, * a = a[1], a[n > * a] = n : 0; }
int arr[10] = { 9,1,2,6,8,11,45,-1,6,4 };
int main() {
s(arr, 10);
for (int i = 0; i < 10; i++) {
printf("%d ", arr[i]);
}
printf("\n");
return 0;
}
What I didn’t show you is the number of times Windows defender went ape and declared it a trojan, every time it compiled! My PC is kept pretty bug free and this is a false positive…
An English mathematician John Conway (who died not that long ago) came up with a very simple cellular automaton that he called Life. This was back in the 1970s and I remember finding his original article in Scientific American while at University.
We had no internet then and I whiled away 10 or so hours trying to make my version of Life run faster. Given that this was 1978 and it was written in BASIC, it’s not surprising that it only did a couple of generations per second on a mainframe. They didn’t give us much CPU time and it was an ICL 1900. My iPhone is probably more powerful!
The rules are simple enough to implement but it’s unlikely you’ll outperform Golly which is what the image shows. That’s written in C++ and has been under near continuous development for the last 15 years.
But part of the fun is writing your own life simulator and watching the patterns explode. I’d call it the minecraft of its day given the amount of computing time spent on this since the 1970s. There are some amazing creations all following these three simple rules.
Any live cell with two or three live neighbours survives.
Any dead cell with three live neighbours becomes a live cell.
All other live cells die in the next generation. Similarly, all other dead cells stay dead.
The grid is just a simple bit field. Each cell is either on or off and the rules determine if new cells are created or if patterns die out.
There are innumerable ones on the web. Here for example is a C/SDL version. Note, it uses SDL1. When I get the time, I’ll build and run it. Comments are in French!
In theory function pointers are straightforward. You have a pointer which is assigned to a function. You then make a call indirectly to that function. But, it’s when the function has parameters passed in and returns things that the definition gets messy. Reading them is hard enough but trying to get it right when you are writing them can waste a lot of time.
Most days I read various websites and one of those is the C programming forum on reddit.com. This has either articles or links to articles an one that was recently posted is about C function pointers and includes a very extensive list of definitions and what they mean with nearly 40 different examples of both legal and not legal examples. The examples are handy; just make sure you don’t use an illegal one. It won’t compile!
The second game is Match Three and I’d made some good progress. You can view some .mp4s from earlier this month here. The first one (MatchThree) shows rotations, something I’d never realised SDL is very good at doing. Graphics are from the excellent Dutch website (it’s in English) Kenney.nl.
The second mp4 (transitions) shows some animations. And the MatchThreeDropping shows pieces both being removed (first rotating and shrinking) and pieces dropping. However it also shows a flaw. Sometimes all the pieces move together, other times (and this is the flaw) it shows them dropping one by one- Mexican wave-like, rather than all moving together.
My original algorithm, which I am now scrapping, had a transitions table. When the space or spaces below a piece became blank, a transition was created which had start and end positions. The piece was removed from the board (a simple 2d array) and reinstated in the board when it had finished moving to the end pixel position.
I think I have a much better method now, I still use a board but each element has a pointer to a piece in a big array of piece structs. I track both the coordinates in the board (0-9,0-9) and in pixels as each piece is 64 x 64. When a space is created in the board, all the pointers are shuffled and each piece is told to move from it’s old pixel position to its new one.
The move algorithm operates purely on the all pieces in the piece array not the board. The flawed algorithm worked on both the board and transition array and was quite messy. Sometimes you have to start with a clean slate than try and fix code that is working correctly.
Sometimes you just need to view or maybe a binary file and here I’ve done that on the compiled file for asteroids.
I can’t recommend doing that, but I wanted to try hexedit on the Raspberry Pi. I ran it against the asteroids compiled program and found the text.
If you look I’ve changed the d in starfield (first line of text) to an e. Then I saved it. The program, not unreasonably crashed when run with an error in the errolog.txt file: Couldn’t open images/starfiele.png
You install hexedit with
sudo apt install hexedit
and run with the file you want to view/edit.
hexedit asteroids
To view all the command press F1. It displays the man page for hexedit. Have fun!
unsigned char c = 241;
long bits = (c * 01001001001ULL & 042104210421ULL) % 017;
printf("Bits = %lu\n",bits);
Remarkably it calculates the number of bits in c and should output “Bits = 5”.
If you don’t believe me, try this program to show all 256 values and the count. If you use c in the for loop instead of i, it never finishes. Well not with Visual C++ 2019!
#include <stdio.h>
int main()
{
for (int i = 0; i < 256; i++){
unsigned char c = i % 256;
long bits = (c * 01001001001ULL & 042104210421ULL) % 017;
printf("c %d #Bits = %lu\n",c, bits);
}
return 0;
}
You can try this out online on one of the various online C compilers. Here’s it on repl.it.
I needed this in a bit of debug code. I wanted it to work like printf where there’s a format string containing one or more % format specifications and then write this into a buffer and dump it where ever.
C has a library stdarg which lets you do this. It’s not the most intuitive but it’s definitely worth understanding.
What I’m wanting to do is a function that does something like this (assume s1,s2 and s3 are char *).
But in my own function and with the ability to have 0,1,2 or how ever many parameters without having to write a separate function for each. Kind of what printf does.
The … represent the variable number of parameters. it’s called the variadic operator. To access the actual parameters needs the various va_ macros and types. For instance va_list is a type that manages the list of parameters. The va_start macro takes the list and the parameter before the list. vsprintf_s is the Microsoft secure version of vsprintf. Both are the variable parameter equivalent of sprintf/sprintf_s.
OutputDebugString is the Windows debug string function. Finally the va_end tidies up everything.
So you use this just like printf, except the output goes to the Debug channel and can be picked up in Visual Studio (if debugging) or by running the SysInternals free DebugView utility.
Note, the original version of this used OutputDebugString but I found it was outputting gibberish. I correctly guessed that it was linking to OutputDebugStringW ; the MBCS version and changing it to OutputDebugStringA (the ASCII version) fixed it. Something to watch out for on Windows.
Well to be fair, it was me that made it unbootable. I’d been reading this Wiki page on configuring the Pi. I’d told it to give the GPU almost a GB of RAM. The Pi is a 4 GB Pi 4B. I did it last night and so this morning, I found it not working at all well.
My first thoughts were I’d messed up the Operating system and so I took the SD card put it in a holder and booted up my old laptop which has Ubuntu 18.04 LTS on it. This page on switchdoc suggested I could do a repair with these commands.
First lsblk to view attached devices. There was a /dev/sdc2 . There was also a /dev/sdc1
Then
sudo fsck -fy /dev/sdc1
That gave information about the drive but not the disk. That took
sudo fsck -fy /dev/sdc2
That took a few seconds and listed information, but still my drive wouldn’t boot back in the Pi.
Then I remembered I’d changed the boot config.txt and it was back with the SD card in the laptop and rebooted that. It showed two devices on the desktop (no need to mount anything) and clicking boot gave me a directory listing of /boot. I edited config.txt and changed the GPU Mem value to 256MB.
That fixed it and my PI is now booting quite happily again. I am now going to make a backup copy! It wouldn’t the end of the world if I had made it permanently unbootable, I’d just burn the OS again. It’s just the time wasted and minor hassles copying files, downloading and reinstalling software. Best avoided if possible!
This is a little bit off-topic for this blog but hey it’s my blog and it is C code and I will be publishing it in full. It’s often said that programmers should not write their own encryption software because most programmers do not have the mathematical background. And I confess that’s me…
However, I thought I’d publish it and put it out there and someone can look at it and say, oh that’s far too easy to break, or maybe not!
The other truism with writing encryption software is that it must not depend upon the algorithm being concealed; the key yes, the algorithm no. So here’s my algorithm.
Generate a 64 byte key. This key has one property, in that it contains each of the 64 numbers 0-63. The order is scrambled. So it might start 0,1,2 but after the bytes have been shuffled (like shuffling cards in a deck) then it might have 43,9,12 and so on. Think of it as a single row with 64 columns. This 64 byte array must be written to disk. It’s a symmetric cipher, the same key is used to encrypt and decrypt.
Take the plain text and process it in blocks of 8 bytes at a time. Split those 8 bytes into 64 individual bits and write each bit to its own stream. So after processing 64 bytes, each stream has a single byte. Now write these 64 bytes to the file but index the column by the key i.e.
for (i=0;i<64;i++)
write(file, data[key[i]]);
So the first byte written would be data[43] then data[9], data[12] and so on.
So you say, that doesn’t sound very complicated. Are you sure it is encrypted?
Well consider our 64 byte key. There are 64! different ways of rearranging the 64 bytes. If I repeat some of my post from three days ago. “If you could do a million a second, it would take you 1.27×1083 seconds or 4.02×1075 years! Or to make it more meaningful it’s this large! 4.02,000,000,000,000,000,000,000,000,000,000,000,000,000,000,000,000,000,000,000,000,000,000,000,000,000 years. That’s approaching (but still far far off) the time for the heat death of the universe which is estimated at 10100!”
Now I don’t know what methods might be used to crack it. Plus if you have some super-dooper fast hardware that can brute force it, it must have some way of recognising that the decrypted data is correct. If before encrypting it, we do a round of obscuring text, maybe something as simple as xoring the text with a repeating set of values, it’s going to make things a wee bit harder.
I welcome any comments on this and as soon as I have finished testing my program, I’ll put the source code up on Github.


 I came across
I came across 
 An English mathematician John Conway (who died not that long ago) came up with a very simple cellular automaton that he called
An English mathematician John Conway (who died not that long ago) came up with a very simple cellular automaton that he called 
 The second game is Match Three and I’d made some good progress. You can view some .mp4s from earlier this month
The second game is Match Three and I’d made some good progress. You can view some .mp4s from earlier this month Sometimes you just need to view or maybe a binary file and here I’ve done that on the compiled file for asteroids.
Sometimes you just need to view or maybe a binary file and here I’ve done that on the compiled file for asteroids. Here’s it on
Here’s it on  I needed this in a bit of debug code. I wanted it to work like printf where there’s a format string containing one or more % format specifications and then write this into a buffer and dump it where ever.
I needed this in a bit of debug code. I wanted it to work like printf where there’s a format string containing one or more % format specifications and then write this into a buffer and dump it where ever.
