C of course doesn’t have generics or templates like C++ does, but I came across Gustav Lou’s C Template library this morning. It provides C equivalents to the following C++ template libraries. Each is done as a header file that you include.
The page on GitHub shows how to use libraries with an example of vector. The string equivalent library str.h would be an interesting one to see just how much of C++ string is supported. C would still never be my language of choice for anything text heavy but if this is better than strcpy, strcat etc. I’ll happily use it. Likewise list and vector. From memory C++ std::array is just a wrapper around the C standard array!
I remember that some other programming language (possibly Go) has a defer mechanism. You can tell it to defer a function call until the end of the function. I think this means, even if you do an early return that all functions that have been deferred will still run. It’s a handy language feature. Alternatives to it ion say C# are try … finally where the finally ensures that code gets runs.
The reason for mentioning this is it’s a possibility for a future inclusion in the next C standard. There’s a quite long article about defer listing benefits. But even better the author Jens Gustedt has provided a reference implementation of it on GitLab.
I’m all in favour of this. Adding new features to C is not something to be done lightly but error checking and handling in C has always been a bit iffy. I’ve never used a SetJmp for example. I do hope that defer gets added to C though I can’t see it being there for a few years.
As part of the crossword grid packing utility, the first stage is building the list of words in a structure in RAM. To keep thing simple I’m going to use an array of char * pointers. The array is limited to a maximum 20 words. If any more are read then they will be discarded.
Just to prove that it worked, I wrote this in Visual Studio and ran it in the debugger. You can see elements 0-9 in the screenshot with the source code in the background.
This is the listing of the program. Note, it doesn’t have a function to free up the memory dynamically allocated for each of the words.
You might wonder about these lines (25 and 26).
if (line[len-1] == '\n')
line[--len] = '\0';
This is needed because when you use fgets to read a line of text it includes a line feed at the end. So the first line in the file Engine is actually 7 characters long with a terminating \n. The malloc on line 27 allocated enough RAM for len + 1 to allow for the terminating 0 at the end of each string. In line 33, if you are on Linux replace strcpy_s with strncpy. Both are safe versions of strcpy. Here’s the full listing.
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <time.h>
#define MAXWORDS 20
#define MAXWORDLENGTH 32
typedef char* pWord;
pWord allwords[MAXWORDS];
int ReadWords(char * filename) {
memset(allwords, 0, sizeof(allwords)); // clear it
char line[MAXWORDLENGTH*2]; // double max size just in case
FILE* fwords;
int errnum = fopen_s(&fwords,filename, "rt");
if (!fwords) {
printf("Missing word file %s", filename);
}
int wordIndex = 0;
while (fgets(line, MAXWORDLENGTH, fwords)) {
int len = strlen(line);
if (!len)
break;
if (line[len-1] == '\n')
line[--len] = '\0';
pWord pNewWord = (pWord)malloc(len + 1); // line 27
if (!pNewWord) {
printf("Error allocating memory");
break;
}
if (wordIndex < MAXWORDS) { // can add to list
strcpy_s(pNewWord, len+1, line); // line 33
allwords[wordIndex++] = pNewWord;
}
}
fclose(fwords);
return wordIndex; // = Count of words
}
int main() {
int numWordsread = ReadWords("words.txt");
}
You are given a list of words. You have to fit them into a grid so that the grid is as small as possible. The words can go horizontal or vertical and can use letters from other words (like in Scrabble). But you can’t have words next to each other except where they share letters like in the picture above. MN BTW is not a valid Scrabble word so this is wrong! (I er borrowed it from somewhere!)
So words can be placed anywhere, in either orientation. Evaluating all the possibilities could probably be done by brute force. But for each word in each position on the board there are n-1 words to be fitted afterwards. Do you try and fit in each alternate word in a different orientation like horizontal then vertical then horizontal?
If there are ten words to fit in say in a starting grid of 20 x 20 and the first word is 6 characters long then it can fit in 15 different places along the top line and on each of the 20 lines so that’s 300 positions. Then if its vertical there another 300 positions. That’s 600 positions to try. And for each of those 600 there’s 9! different combinations of words to fit in. 9! = 362,880.
Of course if the first word and the second word have no letters in common then it may be as well to skip that 2nd word and go onto the 3rd and so on. We want to keep the grid from getting too large with unconnected words. Also We might limit the first word to start in th 6 positions in the top row and maybe only the first and 2nd rows. That vastly reduces the number of combinations to try out. But still it’s a tough thing to program.
C isn’t usually the best language to program anything with text in, but in this case, we’re not building sentences or searching, just looking at arrays of characters and so it might just be suitable.
I’m going to have a go at this and see if it can be done and if so I’ll publish my code but this may take a few days. If so then it could be used as a basis of a word search generator though the rules about words being next to each other could be relaxed plus words run forwards and backwards in both horizontal and vertical orientation and also diagonal.
Previous Puzzle Answer
This was “If I have the integers 4,5,6,7 and 8 and a special C function f so that f(4)=2, f(5) = 5, f(6)=10, f(7)=40 and f(8) = 92. What is the function f?”.Bit of a trick question this as the function is returning the number of unique Queens that could be fitted on a chess board of size n (4×4,5×5..8×8) without being able to attack each other.
Philip Jama has posted a C program on GitHub to arrange the number of Queens on a chessboard of the specified size. So the function wasn’t really a function…
Most of the time I’ve got by configuring VS Code but recently I wasted an hour having managed to completely mess it up. I have a Raspberry Pi version of Asteroids which adds temperature display and game pad support. It’s a useful way to check when I burn a new SD and install VS Code, clang, and all the libSDL2-dev codes that everything is there. If it’s not it won’t compile.
Only this time because I was doing other stuff I decided to create a Projects folder which contained the Asteroids folder and some other stuff and opened Projects as the Folder. I copied the hidden .vscode folder into Projects/Asteroids and tried to compile. Errors. Lots of compile errors. I repeatedly edited the tasks.json file with altered paths but no joy. I spent an hour trying before closing the Folder and reopening it with Asteroids as the Folder and with the original tasks.json. It compiled perfectly.
So the moral of the tale is just keep the level of folders down to one when you open the Folder on the files you are compiling. Do not have subfolders.
Here’s an interesting puzzle (well for some people). If I have the integers 4,5,6,7 and 8 and a special C function f so that f(4)=2, f(5) = 5, f(6)=10, f(7)=40 and f(8) = 92. What is the function f? And no it’s not a simple array containing the numbers 2,5,10,40,92 at positions 4-8!
I also checked the OEIS (Online Encyclopaedia of Integer sequences) and it’s not in there either. Years ago I was fooled by a integer sequence that was the maximum number of electrons in orbital shells but its definitely not that.
Here’s a minor clue. It is game related. Answer in a day or two.
I eventually got the Windows SDL vs TTF comparison program converted to run on Raspberry-pi, after wrestling with VS Code’s Folder. Get it wrong and you can waste hours trying to get it to compile and link. I originally set the Folder (VS Code’s way of managing projects) to the pi/Projects folder (which contained both asteroids and sdlttf folders) but eventually I sussed it and set sdlttf as my Folder. The login user is pi and so the pi folder is my home folder. I created the Projects folder under it.
This time the home brewed print routine (print) took 28x as long as the SDL_ttf compared to 14x on Windows. I used the same text.png and font.ttf files. The times are in the Window caption and read (for those with poor contrast) sdl: 35538.574 ttf: 1235.630. These times are the microsecond times to draw the strings 100x.
Changes were fairly minimal. I changed the fopen_s to fopen (used for error logging) and changed the paths to the two font files. The other change was in the timing which used the Linux versions of hr_time.h/.c and called the diff() function instead of GetElapsedTime().
I’ve zipped up the source file (sdlttf.c) plus timing files and JSON config files for VS Code in the sdlttf_pi.zip file and put it in the LearnConLinux repository on GitHub.
Note I created a projects folder then sdlttf under that. The paths in tasks.json reflect this. To build this you’ll need libsdl2-dev,libsdl2_image_dev and libsdl2-ttf-dev installed. I used clang version 7 (the default installed on pi when you do sudo apt install clang) but I imagine gcc should also build it without any problems.
This matches my conclusions from running the virtually identical Windows version. The sdlttf way is way faster for prerendered strings than my print routine which just blits the characters out of the font bitmap one by one.
Bit twiddling with C is quite a common thing but sometimes it can be hard to understand something quite simple. Here’s a line of code. Can you say what it does? Note that a,b and c are all ints.
c = b ^ ((a ^ b) & -(a < b));
Or how about this which looks quite similar
c = a ^ ((a ^ b) & -(a < b));
The first line puts the minimum of a and b into c, while the second line puts the max of a and b. Both came from a page of bit twiddling hacks by Sean Eron Anderson at Stanford university. The significant thing about these is not that they provide two clever if incomprehensible ways of calculating min and max but they do it without branches.
If you look at the source of min and max in stdlib.h they are defined like this:
Because modern CPUs use instruction caches (pipelines), they try to keep them full through a technique called branch prediction. If a branch happens then the CPU has to read instructions from the wherever the branch goes to and this causes a pipeline stall which slightly slows down processing. So branchless min and max should run faster than branching code, at least in theory.
I tried it on Windows using a small Visual C++ (Well C) program doing the four in a loop 10 million times. I also ran it in 32-bit and 64-bit. All runs were done in release mode which lets the compiler optimise.
Curiously the 32-bit took almost no time at all while the 64-bit took a lot lot longer. There wasn’t much difference between branchless and branch. Possibly the code is too small and the benefits of branchless are less significant because the instructions fall inside the instruction cache for 32-bit while 64-bit may be too big and so is affected by instruction cache misses.
This is the 32-bit time.
fastMin 0.0000000
fastMax 0.1000000
Min 0.1000000
Max 0.1000000
And this is the 64-bit. Quite a lot of difference!
fastMin 1757.6000000
fastMax 1677.9000000
Min 2039.4000000
Max 2134.4000000
This is the code which compiles in Visual C++. You can get the hr_time timing code (for WIndows) from the sdlttf.zip file. I increment and decrement a and b to stop the compiler possibly spotting that the values would be invariant otherwise and doing too-clever optimisation stuff.
#include <math.h>
#include <stdio.h>
#include "hr_time.h"
#define NUMLOOPS 10000000
int a = 1000;
int b = 67;
int c;
double t;
stopWatch s;
int main() {
startTimer(&s);
for (int i = 0; i < NUMLOOPS; i++) {
a++;
b++;
c = b ^ ((a ^ b) & -(a < b));
}
stopTimer(&s);
t = getElapsedTime(&s) * 1000000.0;
printf( "fastMin %8.7f\n", t);
startTimer(&s);
for (int i = 0; i < NUMLOOPS; i++) {
a--;
b--;
c = a ^ ((a ^ b) & -(a < b));
}
stopTimer(&s);
t = getElapsedTime(&s) * 1000000.0;
printf("fastMax %8.7f\n", t);
startTimer(&s);
for (int i = 0; i < NUMLOOPS; i++) {
a++;
b++;
c = min(a, b);
}
stopTimer(&s);
t = getElapsedTime(&s) * 1000000.0;
printf("Min %8.7f\n", t);
startTimer(&s);
for (int i = 0; i < NUMLOOPS; i++) {
a--;
b--;
c = max(a, b);
}
stopTimer(&s);
t = getElapsedTime(&s) * 1000000.0;
printf("Max %8.7f\n", t);
}
John Carmack is a major games developer involved with DOOM, Quake and many other titles. Recently some past things he wrote were published and its interesting particular about inlined code.
You can read the piece here, but I’ll just copy a little bit out. Which of these three coding styles do you prefer?
If you look at the source of Asteroids, you’d probably notice I’m more of an A or B person. I do like readability. Though if you looked back at the assembler code I wrote 30 odd years ago, it was not very modular. I used functions very rarely back then. In those days, you had to do a lot of tricks like unrolling loops to get that extra bit of performance. Now, it’s not quite as important and I’m happy to make it readable.
So I got round to writing that SDL vs TTF timing comparison. However I had to make a few assumptions. The program was written for Windows but easily converts to Linux (apart from the timing code but I did that back in March for Linux) is about 250 lines long. I’ve uploaded it to GitHub, and the zip file contains not only the VS 2019 project and source but all the SDL2 dlls plus a free font MONOFONT.TTF (renamed to font.ttf) and test.png which is the bitmap font as a .png file.
Note you’ll have to edit the sdlttf.c file and change the paths to load the font .png and ttf files in lines 96 and 97.
I’d never used SDL_ttf before though it worked out easy enough. There are three levels of TTF – fast, not so fast and slow but pretty. I went for the fastest setting. The SDL text is in red and the TTF in yellow and are roughly the same height about 30 points.
If you read the caption you’ll see that my bitmap font drawing (I call it SDL) is nearly 14 x slower than TTF. In my code I prerendered the phrase “Sphinx of black quartz, judge my vow” which has all 26 letters a-z but is shorter than standard phrase “the lazy quick fox…”.
SDL_ttf renders the phrase into a surface which is a memory structure in RAM. Calling SDL_CreateTextureFromSurface (line 188) creates a texture from this (it copies the bitmap from RAM to VRAM) and so in my program I was just blitting this texture to the screen. The SDL printing in the print function (Line 157) gets each character, and calls printch (line 143) which works out where in the textFont texture that character and blits it. I’m guessing the overhead of blitting individual characters is what makes it so much slower.
So for fixed phrases where you can prerender the surface and texture, SDL_ttf is way faster and more flexible with colour and to a certain extent size. Colour is set at runtime while size is set when you prerender the font into the surface. If you want different sizes then you need multiple surfaces and corresponding textures for each size. Things like say a score would be a bit slower because it would need to be rendered each time and copied to a texture or prerender all 10 digits and have a texture for each and draw it much like the print method does.
The program is a little rough in places; it was thrown together over three nights.

 C of course doesn’t have generics or templates like C++ does, but I came across Gustav Lou’s C Template library this morning. It provides C equivalents to the following C++ template libraries. Each is done as a header file that you include.
C of course doesn’t have generics or templates like C++ does, but I came across Gustav Lou’s C Template library this morning. It provides C equivalents to the following C++ template libraries. Each is done as a header file that you include. I remember that some other programming language (possibly Go) has a defer mechanism. You can tell it to defer a function call until the end of the function. I think this means, even if you do an early return that all functions that have been deferred will still run. It’s a handy language feature. Alternatives to it ion say C# are try … finally where the finally ensures that code gets runs.
I remember that some other programming language (possibly Go) has a defer mechanism. You can tell it to defer a function call until the end of the function. I think this means, even if you do an early return that all functions that have been deferred will still run. It’s a handy language feature. Alternatives to it ion say C# are try … finally where the finally ensures that code gets runs.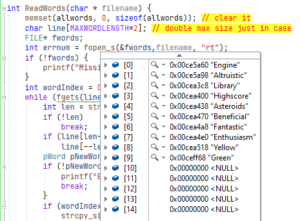 As part of the crossword grid packing utility, the first stage is building the list of words in a structure in RAM. To keep thing simple I’m going to use an array of char * pointers. The array is limited to a maximum 20 words. If any more are read then they will be discarded.
As part of the crossword grid packing utility, the first stage is building the list of words in a structure in RAM. To keep thing simple I’m going to use an array of char * pointers. The array is limited to a maximum 20 words. If any more are read then they will be discarded. You are given a list of words. You have to fit them into a grid so that the grid is as small as possible. The words can go horizontal or vertical and can use letters from other words (like in Scrabble). But you can’t have words next to each other except where they share letters like in the picture above. MN BTW is not a valid Scrabble word so this is wrong! (I er borrowed it from somewhere!)
You are given a list of words. You have to fit them into a grid so that the grid is as small as possible. The words can go horizontal or vertical and can use letters from other words (like in Scrabble). But you can’t have words next to each other except where they share letters like in the picture above. MN BTW is not a valid Scrabble word so this is wrong! (I er borrowed it from somewhere!) Most of the time I’ve got by configuring VS Code but recently I wasted an hour having managed to completely mess it up. I have a Raspberry Pi version of Asteroids which adds temperature display and game pad support. It’s a useful way to check when I burn a new SD and install VS Code, clang, and all the libSDL2-dev codes that everything is there. If it’s not it won’t compile.
Most of the time I’ve got by configuring VS Code but recently I wasted an hour having managed to completely mess it up. I have a Raspberry Pi version of Asteroids which adds temperature display and game pad support. It’s a useful way to check when I burn a new SD and install VS Code, clang, and all the libSDL2-dev codes that everything is there. If it’s not it won’t compile.
 I eventually got the
I eventually got the 

 So I got round to writing that SDL vs TTF timing comparison. However I had to make a few assumptions. The program was written for Windows but easily converts to Linux (apart from the timing code but I did that
So I got round to writing that SDL vs TTF timing comparison. However I had to make a few assumptions. The program was written for Windows but easily converts to Linux (apart from the timing code but I did that